热门关键词:
烧录机,烧录器,自动烧录机,芯片自动烧录机,全自动烧录机,烧录编程器,烧录机厂家,烧录器厂家
烧录器
自动烧录机
烧录编程器
联系我们
了解更多详细信息,请致电
0512-67950666
4000-526-058
或给我们留言
芯原神经网络处理器IP每秒可提供超过3 Tera MAC
芯原神经网络处理器IP每秒可提供超过3 Tera MAC
2017-5-4 作者: 来源:半导体应用
核心提示:芯原股份有限公司(芯原)5月3日宣布,推出一款面向计算机视觉和人工智能应用的高度可扩展和可编程的处理器VIP8000。在16nm FinFET工艺制程下,VIP8000可提供每秒超过3 Tera MACs的计算能力,能耗效率高于1.5 GMAC/秒/毫瓦,并且占用硅片面积是业内最小。
芯原股份有限公司(芯原)5月3日宣布,推出一款面向计算机视觉和人工智能应用的高度可扩展和可编程的处理器VIP8000。在16nm FinFET工艺制程下,VIP8000可提供每秒超过3 Tera MACs的计算能力,能耗效率高于1.5 GMAC/秒/毫瓦,并且占用硅片面积是业内最小。
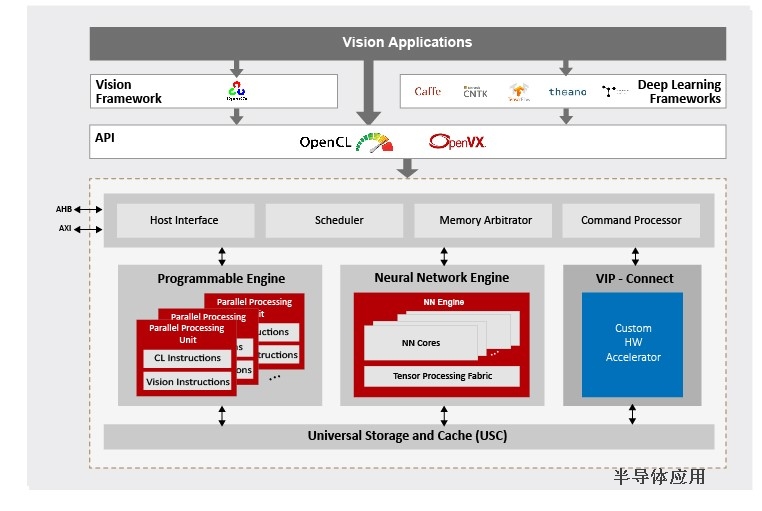
Vivante VIP8000由高度多线程的并行处理单元、神经网络单元和通用存储缓存单元组成。VIP8000可以直接导入由Caffe和TensorFlow等主流深度学习框架生成的神经网络,并可利用OpenVX框架将神经网络集成到其他计算机视觉功能模块中。它支持当前所有的主流神经网络模型(包括AlexNet、GoogleNet、ResNet、VGG、Faster-RCNN、Yolo、SSD、FCN和SegNet)和层类型(包括卷积和去卷积、扩张、FC、池化和去池化、各种规范化层和激活函数、张量重塑、逐元素运算、RNN和LSTM功能),旨在促进新型神经网络和新型层的采用。神经网络单元支持定点8位精度和浮点16位精度,并支持混合模式应用,以实现最佳计算效率和准确率。
Vivante VIP8000的VIP-Connect™接口支持客户快速集成专用硬件加速单元,使之与标准的Vivante VIP8000硬件单元实现协同运作。该处理器由OpenCL或OpenVX进行编程,并在含客户专用硬件加速单元在内的硬件单元中采用统一的编程模型。所有硬件单元同时工作,共享缓存数据,可显著减少带宽。
为了更好地服务于不同细分市场的嵌入式产品,Vivante VIP8000可以灵活配置,其并行处理单元、神经网络单元和通用存储单元分别具有可扩展性,且ACUITY™ SDK可提供培训和整套IDE工具。
热门文章查看更多+
热门产品




